IDEA
IDEA
 Java
Java
 SpringBoot
SpringBoot
 面试题
面试题
 工具
工具
 JDK下载
JDK下载
从0开始搭建一套完整的ELK分布式日志管理系统

准备工作
虚拟机搭建
参考 基于VirtualBox搭建Linux(CentOS 7)虚拟机环境(学习必备技能):https://blog.lupf.cn/articles/2020/04/04/1586001434581.html
Elasticsearch安装
参考 Elasticsearch 6.6.0 集群搭建:https://blog.lupf.cn/articles/2020/04/22/1587535463629.html
kafka安装
参考 并发(七)之分布式异步更新:Zookeeper+Kafka实现数据分布式异步更新 : https://blog.lupf.cn/articles/2020/04/17/1587096190497.html
JDK安装
以上文章中都有包含JDK的安装
ELK架构图
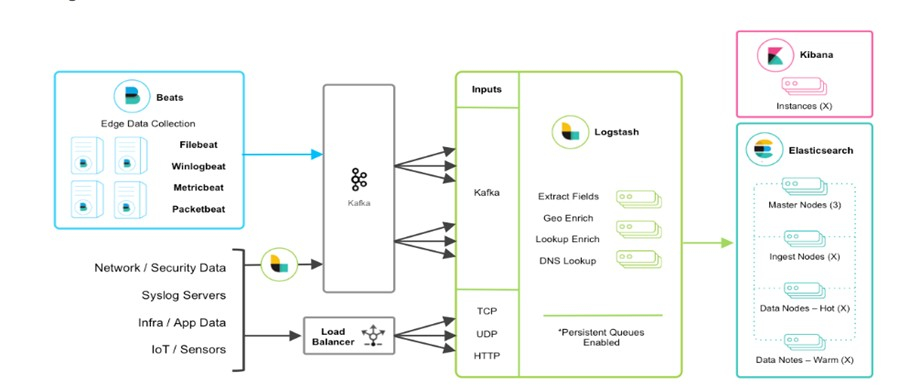
ELK流程图
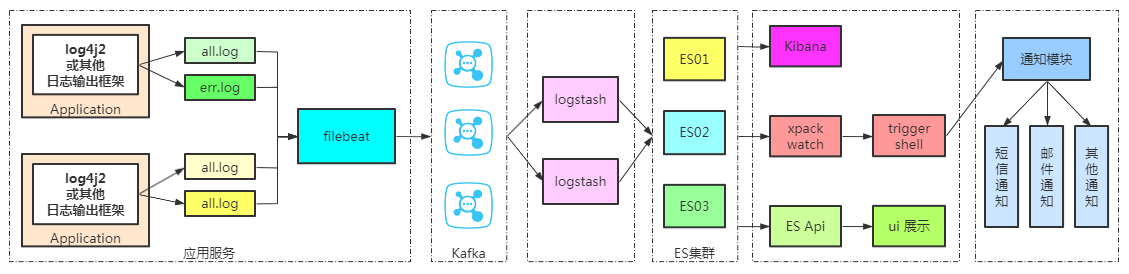
日志生产;
服务通过日志框架输出的日志,Nginx产生的日志;也可以是任何形式输出的日志文件。日志抓取(filebeat);
通过配置,监控抓取符合规则的日志文件,并将抓取到的每条数据发送给kafkakafka;
主要起到削峰填谷,ELK高可用的关键作用;当流量过大,kafka可以起到很好的缓冲作用,降低下游的压力;当下游的logstash或ES故障,也可以很好保证数据的完整性logstash;
消费kafka的数据,并将数据持久化到ES或者其他持久化框架Elasticsearch;
持久化数据,并提供分布式检索功能Kibana;
展示ES中的数据xpack watch;
监控异常通知模块;
将监控到的告警通知给相关责任人
项目日志规范
为什么要规范?只有规范之后的日志,在后续的抓取、整理同步至ES以及查看都会带来很多便利 , 请参考SpringBoot日志的链路追踪 : https://lupf.cn/articles/2020/06/04/1591273110824.html ; 建议优先阅读一下这篇文章 , 后续关于日志的拦截及解析都是基于这里的日志规则进行的; 具体格式如下:
// 完整格式
[%d{yyyy-MM-dd'T'HH:mm:ss.SSSZZ}] [%X{requestId}] [%level{length=5}] [%thread-%tid] [%logger] [%X{hostName}] [%X{localIp}] [%X{clientIp}] [%X{applicationName}] [%X{requestUri}] [%F,%L,%C,%M] [%m] ## '%ex'%n
// 以下是详细说明
// 其中%X打头的都是自定义的日志 需要通过DMC设置
[%d{yyyy-MM-dd'T'HH:mm:ss.SSSZZ}] //当前的时间
[%X{requestId}] // 本次请求的唯一ID
[%level{length=5}] // 日志级别
[%thread-%tid] // 线程id
[%logger] // loger对应的class
[%X{hostName}] // 服务部署的主机名
[%X{localIp}] // 服务部署的主机ip
[%X{clientIp}] //客户端请求的ip
[%X{applicationName}] //应用名称
[%X{requestUri}] // 调用的地址
[%F,%L,%C,%M] // 当前日志所处的类的信息
[%m] // 打印的消息
## '%ex' // 异常信息 使用单引号包裹起来是够了方便后续的logstash的
%n // 换行
filebeat安装
-
下载
// 迅雷下载 https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-6.6.0-linux-x86_64.tar.gz -
上传至服务器解压
cd /usr/local/src tar -zxvf filebeat-6.6.0-linux-x86_64.tar.gz mv filebeat-6.6.0-linux-x86_64 /usr/local/filebeat-6.6.0 cd /usr/local/filebeat-6.6.0 -
filebeat.yml配置
#============== Filebeat prospectors =========== filebeat.prospectors: - type: log paths: - /usr/local/src/logs/log4j2-demo/all.log # - /usr/local/src/logs/*/*.log document_type: "all-log" fields: logbiz: log4j2-demo # 项目名称 log_topic: all-log-log4j2-demo # kafka的topic evn: dev multiline: pattern: '^\[' #指定多行匹配的表达式 以[开头的标识一行新的数据 negate: true # 是否匹配到 match: after # 没有匹配上正则合并到上一行末尾 max_lines: 1000 # 最大未匹配上的行数 timeout: 2s # 指定时间没有新的日志 就不等待后面的日志输入 - type: log #定义多个输入 paths: - /usr/local/src/logs/log4j2-demo/error.log # - /usr/local/src/logs/*/*.log document_type: "err-log" fields: logbiz: log4j2-demo log_topic: err-log-log4j2-demo # kafka的topic evn: dev multiline: pattern: '^\[' #指定多行匹配的表达式 以[开头的标识一行新的数据 negate: true # 是否匹配到 match: after # 没有匹配上正则合并到上一行末尾 max_lines: 1000 # 最大未匹配上的行数 timeout: 2s # 指定时间没有新的日志 就不等待后面的日志输入 ## 定义输出的方式 output.kafka: enabled: true # 启动 hosts: ["192.168.1.160:9092"] #kafka的ip和port topic: '%{[fields.log_topic]}' #指定输出到的topicname 也就是上面定义的变量 partition.hash: # 分区规则 hash reachable_only: true compression: gzip # 数据压缩 max_message_bytes: 1000000 # 最大的消息字节数 required_acks: 1 # kafka ack的方式 0:丢出去就好了 1:有一个响应就好了 -1:所有节点响应才算成功 logging.to_files: true # -
测试配置
cd /usr/local/filebeat-6.6.0 ./filebeat -c filebeat.yml -configtest
-
kafka创建topic
cd /usr/local/kafka/ bin/kafka-topics.sh --zookeeper cache1000:2181,cache1001:2181,cache1002:2181 --topic all-log-log4j2-demo --replication-factor 1 --partitions 1 --create bin/kafka-topics.sh --zookeeper cache1000:2181,cache1001:2181,cache1002:2181 --topic err-log-log4j2-demo --replication-factor 1 --partitions 1 --create // 查看topic的详情 bin/kafka-topics.sh --zookeeper cache1000:2181,cache1001:2181,cache1002:2181 --topic all-log-log4j2-demo --describe
-
启动filebeat
cd /usr/local/filebeat-6.6.0 ./filebeat 1>/dev/null 2>&1 & ps -ef | grep filebeat
-
产生日志数据并确定kafka是否拿到了数据
cd /tmp/kafka-logs/err-log-log4j2-demo-0 ll cd /tmp/kafka-logs/all-log-log4j2-demo-0 ll // 看到文件不为空,说明filebeat生产的数据kafka已经收到
logstash
-
下载
// 迅雷下载 https://artifacts.elastic.co/downloads/logstash/logstash-6.6.0.tar.gz // 上传至任意主机 /usr/local/src 目录下 -
解压
cd /usr/local/src tar -zxvf logstash-6.6.0.tar.gz mv logstash-6.6.0 /usr/local/logstash-6.6.0 -
添加配置
grok内置属性 : https://lupf.cn/articles/2020/08/17/1597661487154.htmlmkdir /usr/local/logstash-6.6.0/script vim logstash-script.conf # 添加以下配置 # 输入从kafka input { kafka { topics_pattern => "all-log-.*" # 也可以模糊匹配 如:all-log.* bootstrap_servers => "192.168.1.160:9092" # kafka的ip 端口 codec => json # 数据格式 consumer_threads => 1 # 对应partition的数量 decorate_events => true #auto_offset_rest => "latest" # 默认值就是这个 group_id => "all-logs-group" # kafka的消费组 } kafka { topics_pattern => "err-log-.*" # 也可以模糊匹配 如:err-log-* 这样就可以匹配到 err-log-product err-log-user bootstrap_servers => "192.168.1.160:9092" # kafka的ip 端口 codec => json # 数据格式 consumer_threads => 1 # 对应partition的数量 decorate_events => true #auto_offset_rest => "latest" # 默认值就是这个 group_id => "err-logs-group" # kafka的消费组 } } filter { ruby { code => "event.set('index_time',event.timestamp.time.localtime.strftime('%Y.%m.%d'))" } ## 这里匹配的是filebeat中的fields.log_topic字段 if "all-log" in [fields][log_topic] { grok { ## 表达式 ## 这里的表达式的定义需要和真实的lo4j2中定义的规则保持一致;否则将无法匹配上 match => ["message","\[%{NOTSPACE:currentDataTime}\] \[%{NOTSPACE:requestId}\] \[%{NOTSPACE:level}\] \[%{NOTSPACE:thread-id}\] \[%{NOTSPACE:logger}\] \[%{DATA:hostName}\] \[%{DATA:localIp}\] \[%{DATA:clientIp}\] \[%{DATA:applicationName}\] \[%{DATA:requestUrl}\] \[%{DATA:location}\] \[%{DATA:loginfo}\] ## (\'\'|%{QUOTEDSTRING:throwable})"] } } if "err-log" in [fields][log_topic] { grok { ## 表达式 match => ["message","\[%{NOTSPACE:currentDataTime}\] \[%{NOTSPACE:requestId}\] \[%{NOTSPACE:level}\] \[%{NOTSPACE:thread-id}\] \[%{NOTSPACE:logger}\] \[%{DATA:hostName}\] \[%{DATA:localIp}\] \[%{DATA:clientIp}\] \[%{DATA:applicationName}\] \[%{DATA:requestUrl}\] \[%{DATA:location}\] \[%{DATA:loginfo}\] ## (\'\'|%{QUOTEDSTRING:throwable})"] } } } ## 输出方式 ## 到控制台 当测试无误之后,可以将此输出关闭 output { stdout { codec => rubydebug } } output { if "all-log" in [fields][log_topic] { elasticsearch { hosts => ["192.168.1.170:9200"] # es的ip 端口 # 用户名 密码 # user => "admin" # password => "admin" # 索引名称(index) # 索引格式:all-log-应用名称-按天分组 # [fields][logbiz]为filebeat中定义的变量 index => "all-log-%{[fields][logbiz]}-%{index_time}" # 是否嗅探集群 # 通过嗅探机制解析es集群的负载均衡发送日志 sniffing => true # logstash默认自带一个mapping模版,进行模版覆盖 template_overwrite => true } } if "err-log" in [fields][log_topic] { elasticsearch { hosts => ["192.168.1.170:9200"] # es的ip 端口 # 用户名 密码 # user => "admin" # password => "admin" # 索引名称(index) # 索引格式:all-log-应用名称-按天分组 # [fields][logbiz]为filebeat中定义的变量 index => "err-log-%{[fields][logbiz]}-%{index_time}" # 是否嗅探集群 # 通过嗅探机制解析es集群的负载均衡发送日志 sniffing => true # logstash默认自带一个mapping模版,进行模版覆盖 template_overwrite => true } } } -
启动
cd /usr/local/logstash-6.6.0 // 前台启动 方便观察数据及日志 ./bin/logstash -f ./script/logstash-script.conf & // 后台启动 nohup ./bin/logstash -f ./script/logstash-script.conf 1>/dev/null 2>&1 & // jps查看是否有Logstash的进程 jps -
logstash的输出
// 以下是产生的日志数据 [2020-04-22T21:35:28.164+08:00] [4562f064-a59f-420d-8673-f9810ef1361c] [INFO] [http-nio-8080-exec-3-21] [com.lupf.log4j2demo.controller.Log4j2Controller] [elasticsearch0000] [192.168.1.170] [192.168.1.82] [log4j2-demo] [/info] [Log4j2Controller.java,14,com.lupf.log4j2demo.controller.Log4j2Controller,info] [我是info日志!!!] ## '' // logstash 接收到kafka的消息并输出的对象 { "log" => { "file" => { "path" => "/usr/local/src/logs/log4j2-demo/all.log" } }, "@version" => "1", "currentDataTime" => "2020-04-23T13:51:58.396+08:00", "input" => { "type" => "log" }, "host" => { "name" => "elasticsearch0000" }, "beat" => { "name" => "elasticsearch0000", "hostname" => "elasticsearch0000", "version" => "6.6.0" }, "source" => "/usr/local/src/logs/log4j2-demo/all.log", "index_time" => "2020.04.23", "requestUrl" => "/info", "offset" => 69870, "message" => "[2020-04-23T13:51:58.396+08:00] [54452aa5-8a5c-4518-8e43-be347c55ff09] [INFO] [http-nio-8080-exec-7-25] [com.lupf.log4j2demo.controller.Log4j2Controller] [elasticsearch0000] [192.168.1.170] [192.168.1.82] [log4j2-demo] [/info] [Log4j2Controller.java,14,com.lupf.log4j2demo.controller.Log4j2Controller,info] [我是info日志!!!] ## ''", "applicationName" => "log4j2-demo", "logger" => "com.lupf.log4j2demo.controller.Log4j2Controller", "prospector" => { "type" => "log" }, "loginfo" => "我是info日志!!!", "thread-id" => "http-nio-8080-exec-7-25", "@timestamp" => 2020-04-23T05:51:59.763Z, "clientIp" => "192.168.1.82", "level" => "INFO", "location" => "Log4j2Controller.java,14,com.lupf.log4j2demo.controller.Log4j2Controller,info", "hostName" => "elasticsearch0000", "fields" => { "log_topic" => "all-log-log4j2-demo", "logbiz" => "log4j2-demo", "evn" => "dev" }, "requestId" => "54452aa5-8a5c-4518-8e43-be347c55ff09", "localIp" => "192.168.1.170" } -
查看kafka的消费情况
cd /usr/local/kafka/ bin/kafka-consumer-groups.sh --bootstrap-server cache1000:9092,cache1001:9092,cache1002:9092 --describe --group err-logs-group bin/kafka-consumer-groups.sh --bootstrap-server cache1000:9092,cache1001:9092,cache1002:9092 --describe --group all-logs-group
logstash输入、过滤器,输出测试
当如果上面的 logstash配置导致输入、过滤器、输出的不对,就可以通过以下的方式进行配置测试,快速定位问题或者配置匹配调整;
-
定义一个手动输入的配置文件
cd /usr/local/logstash-6.6.0 vim script/test.conf // 加入以下配置 # 手动输入 input { stdin { } } # 过滤器 filter{ grok{ # 测试匹配IP match => {"message" => "%{IPV4:ip}"} } } # 输出 output { stdout { } } -
通过以上的配置文件启动logstash
cd /usr/local/logstash-6.6.0 ./bin/logstash -f ./script/test.conf // 然后直接输入想要测试的文本,回车就可以看见结果;如: 192.168.1.123 aabbcc 11223344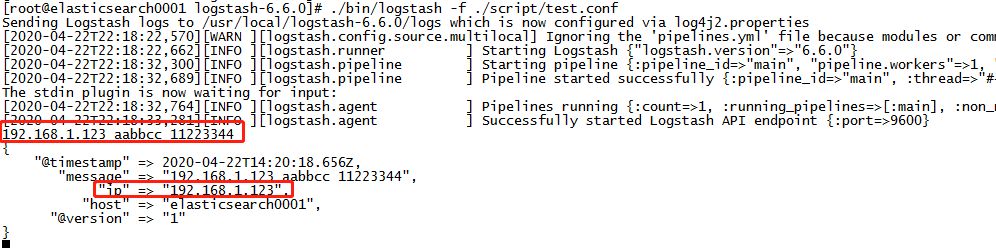
Kibana日志信息查看
-
进入kibana
// kibana监听的是5601端口 http://elasticsearch:5601 -
优先查看索引是否是正常的
GET /_cat/indices?v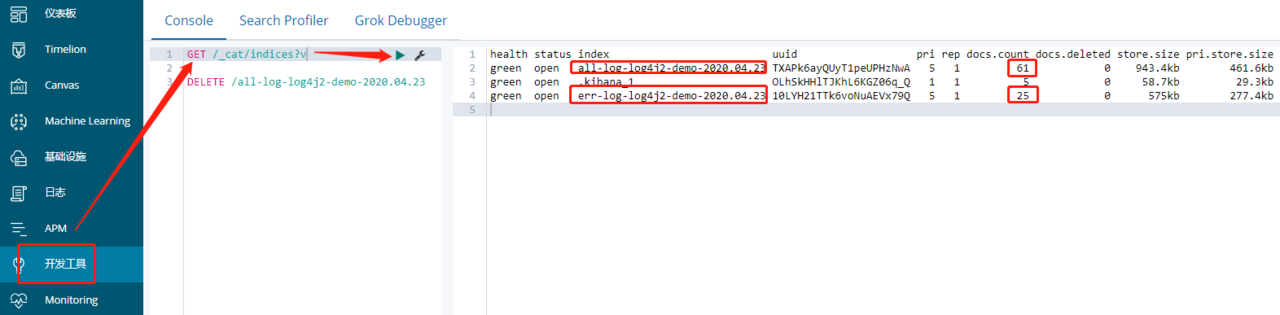
-
配置索引管理
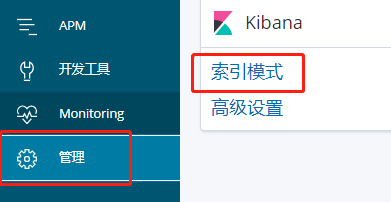
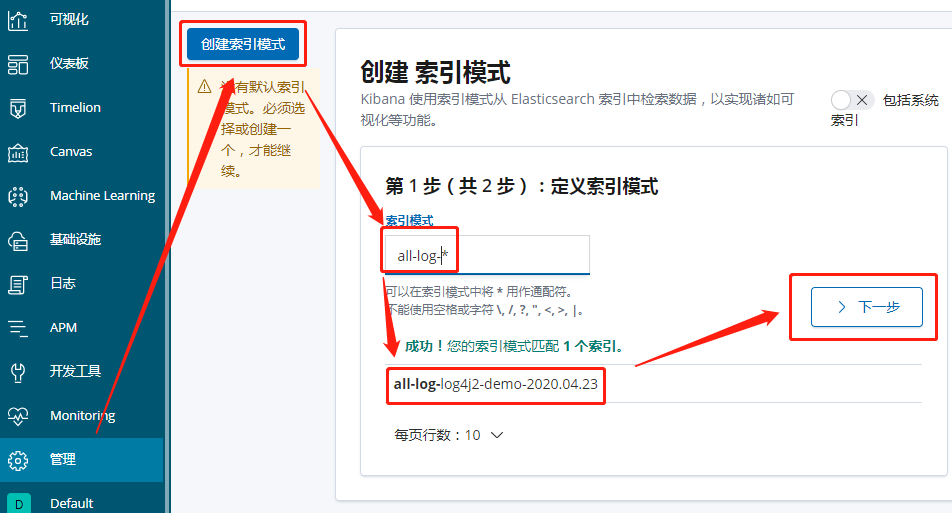
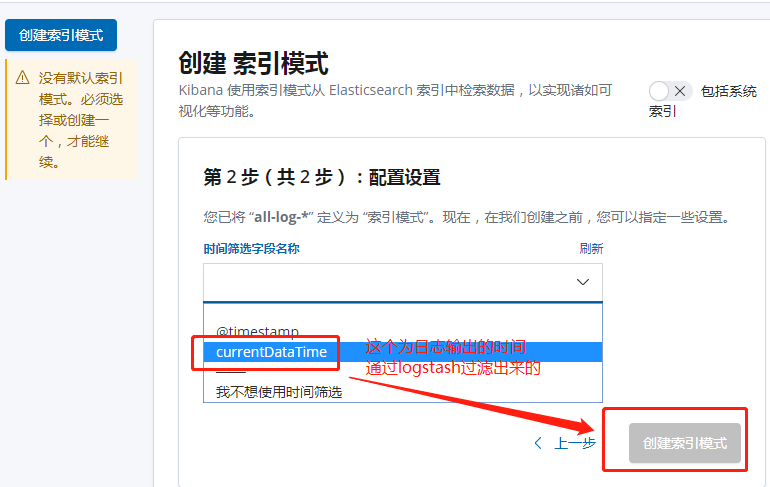
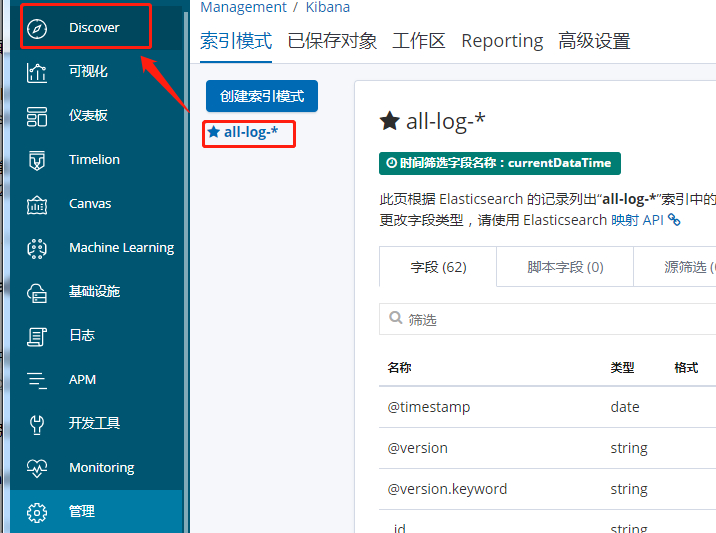
-
日志查看
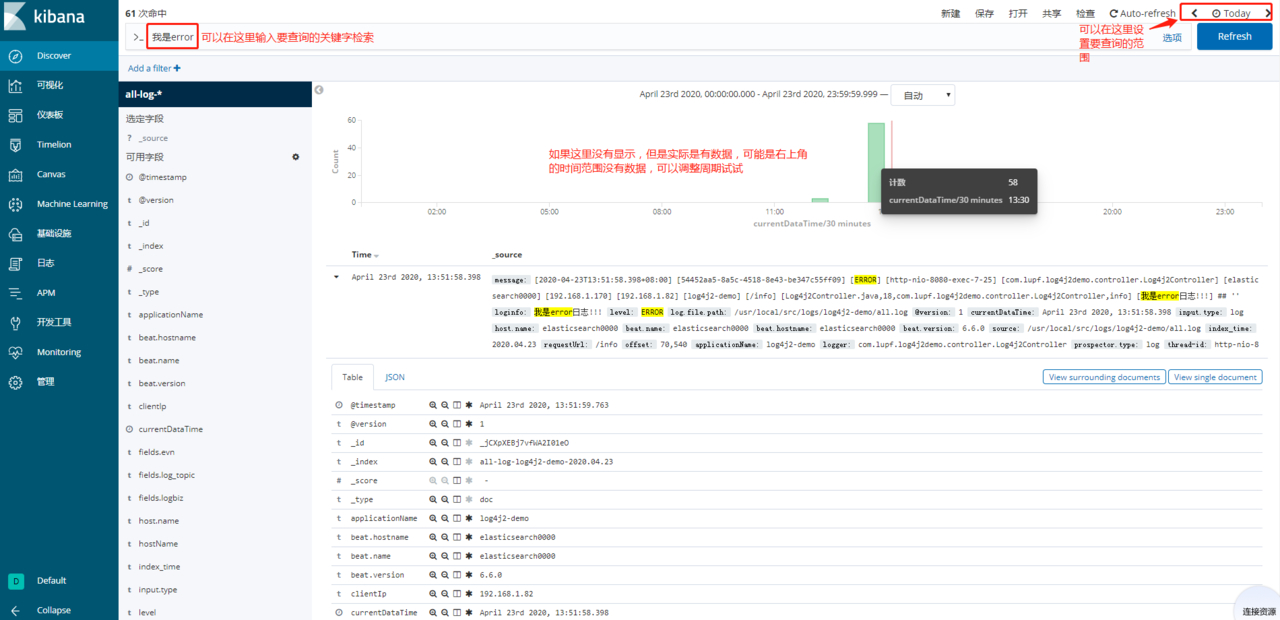
到此!一个从0搭建的ELK技术栈即完成!!!