 IDEA
IDEA
 Java
Java
 SpringBoot
SpringBoot
 面试题
面试题
 工具
工具
 JDK
JDK
Storm2.x集群搭建及SpringBoot+Storm实现词频统计测试

准备3台机器
-
cache1000:192.168.1.160 用来部署nimbus、ui管理平台和zookeeper
-
cache1001:192.168.1.161 用来部署supervisor 和 zookeeper
-
cache1002:192.168.1.162 用来部署supervisor 和 zookeeper
-
配置hosts
192.168.1.160 cache1000 192.168.1.161 cache1001 192.168.1.162 cache1002 -
下载最新的storm
// 这里包含了所有的版本 http://storm.apache.org/downloads.html // 下载2.1.0的版本 cd /usr/local/src wget https://mirror.bit.edu.cn/apache/storm/apache-storm-2.1.0/apache-storm-2.1.0.tar.gz
JDK 8安装及ZK集群安装
参考并发(七)之分布式异步更新:Zookeeper+Kafka实现数据分布式异步更新 ,其中包含了JDK的安装及zk集群的搭建
Storm部署
安装之前确保JDK 8和ZK已经部署好且能正常使用
-
解压
// 创建数据目录 mkdir -p /var/storm/data cd /usr/local/src/ tar -zxvf apache-storm-2.1.0.tar.gz mv apache-storm-2.1.0 /usr/local/storm cd /usr/local/storm -
修改配置
vim /usr/local/storm/conf/storm.yaml // 修改一下配置 #zookeeper集群的地址 #cache1000...跟别都是主机名 在/var/hosts配置了映射关系 storm.zookeeper.servers: - "cache1000" - "cache1001" - "cache1002" #zk的端口,默认就是2181 storm.zookeeper.port: 2181 #nimbus的主机 nimbus.seeds: ["cache1000"] #数据保存的本地路径 storm.local.dir: "/var/storm/data" #supervisor允许启动多少个端口,一个端口代表一个worker supervisor.slots.ports: - 6700 - 6701 - 6702 - 6703 #管理平台的端口,默认8080,防止冲突的话可以修改 ui.port: 8082 -
拷贝配置文件到其他机器
// 也可以手动拷贝 scp -r /usr/local/storm/conf/storm.yaml root@cache1001:/usr/local/storm/conf/storm.yaml scp -r /usr/local/storm/conf/storm.yaml root@cache1002:/usr/local/storm/conf/storm.yaml -
配置环境变量(可跳过)
// 为了方便,可以配置环境变量 vim ~/.bash_profile // 添加 export STORM_HOME=/usr/local/storm // PATH追加 :$STORM_HOME/bin // 刷新配置 source ~/.bash_profile // 其他机器可以使用scp拷贝过去 scp -r ~/.bash_profile root@cache1001:~/.bash_profile scp -r ~/.bash_profile root@cache1002:~/.bash_profile // 每台机器都刷新配置 source ~/.bash_profile // 测试环境变量 storm -h -
启动服务nimbus
// cache1000 启动nimbus 和 ui管理平台 // 配置了环境变量的启动方式 storm nimbus >/dev/null 2>&1 & storm ui >/dev/null 2>&1 & // 未配置环境变量的启动方式 cd /usr/local/storm/bin ./storm nimbus >/dev/null 2>&1 & ./storm ui >/dev/null 2>&1 & // 查看进程 jps | grep Nimbus jps | grep UIServer
-
启动supervisor
// cache1001和cache1002启动supervisor // 配置了环境变量的启动方式 storm supervisor >/dev/null 2>&1 & // 未配置环境变量的启动方式 cd /usr/local/storm/bin ./storm supervisor >/dev/null 2>&1 & // 查看进程 jps | grep Supervisor
-
启动logviewer(所有节点)
storm logviewer >/dev/null 2>&1 & // 或 cd /usr/local/storm/bin ./storm logviewer >/dev/null 2>&1 &
-
管理页面
// 及图IP和主机名根据个人的实际情况来 // window别名访问需要在: C:\Windows\System32\drivers\etc\hosts 文件中配置别名映射 http://cache1000:8082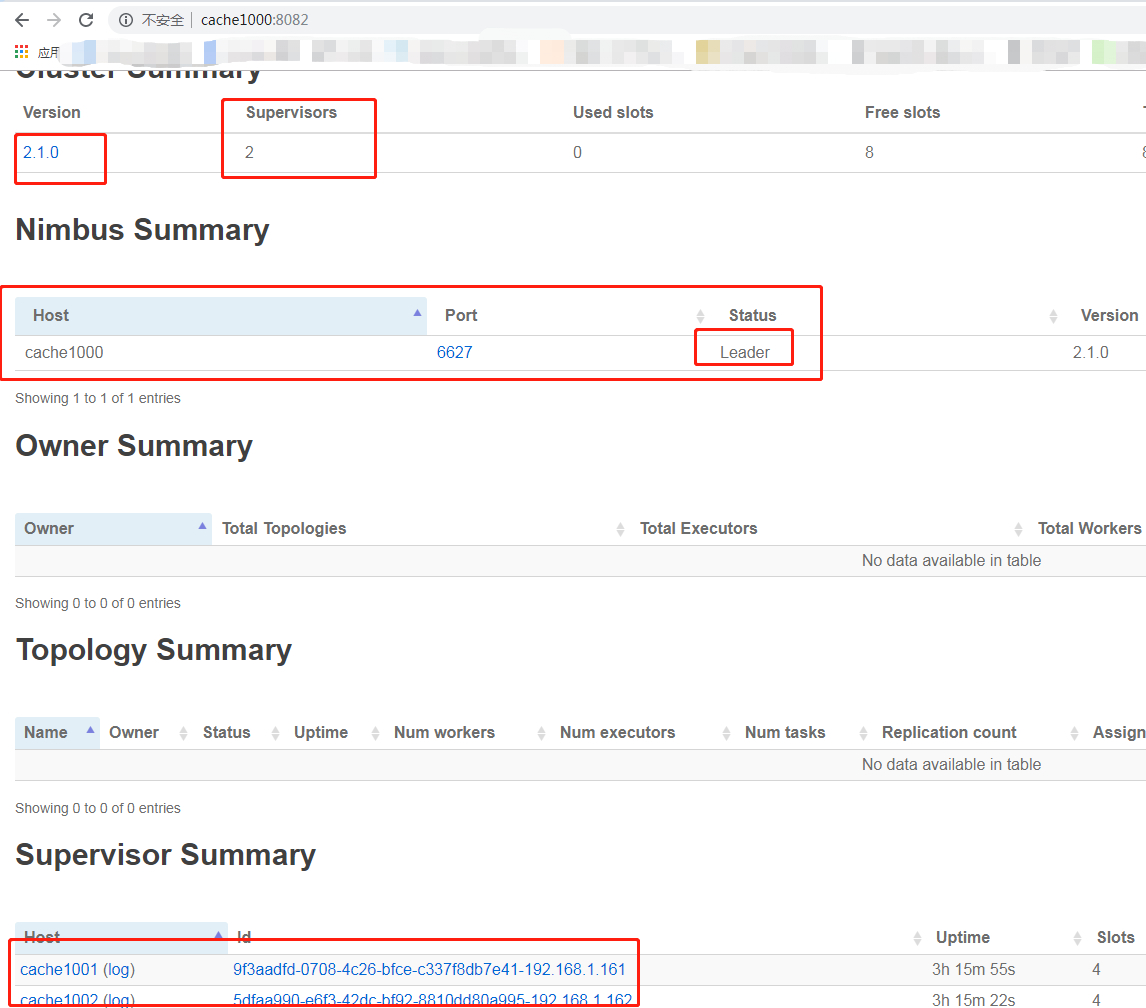
基于SpringBoot的词频统计
-
依赖
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter</artifactId> <exclusions> <exclusion> <groupId>org.apache.logging.log4j</groupId> <artifactId>log4j-to-slf4j</artifactId> </exclusion> </exclusions> </dependency> <dependency> <groupId>org.apache.storm</groupId> <artifactId>storm-core</artifactId> <version>1.2.3</version> <!--在本地模式运行的时候需要把下面的给注释掉--> <!--<scope>provided</scope>--> </dependency> <dependency> <groupId>com.codahale.metrics</groupId> <artifactId>metrics-core</artifactId> <version>3.0.2</version> </dependency> -
插件
<build> <sourceDirectory>src/main/java</sourceDirectory> <plugins> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-jar-plugin</artifactId> </plugin> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-shade-plugin</artifactId> <version>2.3</version> <configuration> <createDependencyReducedPom>true</createDependencyReducedPom> <filters> <filter> <artifact>*:*</artifact> <excludes> <exclude>META-INF/*.SF</exclude> <exclude>META-INF/*.sf</exclude> <exclude>META-INF/*.DSA</exclude> <exclude>META-INF/*.dsa</exclude> <exclude>META-INF/*.RSA</exclude> <exclude>META-INF/*.rsa</exclude> <exclude>META-INF/*.EC</exclude> <exclude>META-INF/*.ec</exclude> <exclude>META-INF/MSFTSIG.SF</exclude> <exclude>META-INF/MSFTSIG.RSA</exclude> </excludes> </filter> </filters> </configuration> <executions> <execution> <phase>package</phase> <goals> <goal>shade</goal> </goals> <configuration> <transformers> <!-- <transformer implementation="org.apache.maven.plugins.shade.resource.ServicesResourceTransformer"/> <transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer"> <mainClass>org.durcframework.core.MainCore</mainClass> </transformer>--> </transformers> </configuration> </execution> </executions> </plugin> <plugin> <groupId>org.codehaus.mojo</groupId> <artifactId>exec-maven-plugin</artifactId> <version>1.2.1</version> <executions> <execution> <goals> <goal>exec</goal> </goals> </execution> </executions> <configuration> <executable>java</executable> <includeProjectDependencies>true</includeProjectDependencies> <includePluginDependencies>false</includePluginDependencies> <classpathScope>compile</classpathScope> <mainClass></mainClass> </configuration> </plugin> </plugins> </build> -
创建Spout,用于源源不断的输出原始数据
import lombok.extern.slf4j.Slf4j; import org.apache.storm.spout.SpoutOutputCollector; import org.apache.storm.task.TopologyContext; import org.apache.storm.topology.OutputFieldsDeclarer; import org.apache.storm.topology.base.BaseRichSpout; import org.apache.storm.tuple.Fields; import org.apache.storm.tuple.Values; import org.apache.storm.utils.Utils; import java.util.Map; import java.util.Random; @Slf4j public class ProverbSpout extends BaseRichSpout { TopologyContext context; SpoutOutputCollector collector; Random random; /** * 做初始化相关的工作 * 如初始化连接池 * 创建http连接 等 * * @param map * @param topologyContext 拓扑上下文对象 * @param spoutOutputCollector 用于发射数据的collector */ @Override public void open(Map map, TopologyContext topologyContext, SpoutOutputCollector spoutOutputCollector) { context = topologyContext; collector = spoutOutputCollector; random = new Random(); } @Override public void nextTuple() { Utils.sleep(100); String[] proverbs = new String[5]; // 没谁瞧不起你,因为别人根本就没瞧你,大家都很忙的 proverbs[0] = "Nobody looks down on you because everybody is too busy to look at you"; // 深谙世故却不世故,才是最成熟的善良 proverbs[1] = "Thoroughly understanding the world but not sophisticated is the maturest kindness"; // 如果只是相见,却不能在一起,那宁愿从未相遇 proverbs[2] = "If we can only encounter each other rather than stay with each other then I wish we had never encountered"; // 当有人离开你的生活时,随他们去吧。这只是给更好的人留足了进入你生活的空间 proverbs[3] = "When someone walk out your life let them They are just making more room for someone else better to walk in"; // 要努力使每一天都开心而有意义,不为别人,为自己 proverbs[4] = "Strive to make every day joyful and meaningful not for others, but for myself"; int i = random.nextInt(proverbs.length); String proverb = proverbs[i]; // new Values就是构建一个tuple(元组) // tuple是最小的数据单元 // 无数个tuple组成的流就是stream log.info("发射谚语{}", proverbs); collector.emit(new Values(proverb)); } /** * 用于定义发射出去的tuple中field的名称 * * @param outputFieldsDeclarer */ @Override public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) { // 这里定义字段名称为proverbs(谚语) outputFieldsDeclarer.declare(new Fields("proverb")); } } -
创建句子拆分的Bolt
import org.apache.storm.task.OutputCollector; import org.apache.storm.task.TopologyContext; import org.apache.storm.topology.OutputFieldsDeclarer; import org.apache.storm.topology.base.BaseRichBolt; import org.apache.storm.tuple.Fields; import org.apache.storm.tuple.Tuple; import org.apache.storm.tuple.Values; import java.util.Map; public class SplitProverb extends BaseRichBolt { OutputCollector collector; /** * bolt的初始化方法 * * @param map * @param topologyContext * @param outputCollector bolt的tuple发射器 */ @Override public void prepare(Map map, TopologyContext topologyContext, OutputCollector outputCollector) { collector = outputCollector; } /** * 会接受到spout发射出来的谚语 * * @param tuple */ @Override public void execute(Tuple tuple) { String proverb = tuple.getStringByField("proverb"); String[] words = proverb.split(" "); for (String word : words) { collector.emit(new Values(word)); } } /** * 定于bolt发射出去的tuple中field的名称 * * @param outputFieldsDeclarer */ @Override public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) { // 这里定义为word outputFieldsDeclarer.declare(new Fields("word")); } } -
词频的Bolt
import lombok.extern.slf4j.Slf4j; import org.apache.storm.topology.BasicOutputCollector; import org.apache.storm.topology.OutputFieldsDeclarer; import org.apache.storm.topology.base.BaseBasicBolt; import org.apache.storm.tuple.Fields; import org.apache.storm.tuple.Tuple; import java.util.HashMap; import java.util.Map; @Slf4j public class WordCount extends BaseBasicBolt { // 统计词频 Map<String, Long> counts = new HashMap<>(); @Override public void execute(Tuple tuple, BasicOutputCollector basicOutputCollector) { // 获取到前一个task发射出来的tuple String word = tuple.getStringByField("word"); Long count = counts.get(word); if (null == count) { count = 0l; } count++; counts.put(word, count); log.info("{}词频{}次", word, count); } @Override public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) { // 声明field outputFieldsDeclarer.declare(new Fields("word", "count")); } } -
创建词频的Topology
import org.apache.storm.Config; import org.apache.storm.LocalCluster; import org.apache.storm.StormSubmitter; import org.apache.storm.topology.TopologyBuilder; import org.apache.storm.tuple.Fields; import org.apache.storm.utils.Utils; public class WordCountMain { public static void main(String[] args) { TopologyBuilder builder = new TopologyBuilder(); // 第一个参数 名称 // 第二个参数 实例化一个spout的对象 // 第三个参数 指定spout的executor有几个 builder.setSpout("proverbSpout", new ProverbSpout(), 2); builder.setBolt("splitProverb", new SplitProverb(), 4). setNumTasks(8) .shuffleGrouping("proverbSpout"); // 通过fieldsGrouping指定group的field可以将相同的单词发射到下游的同一个task中去 builder.setBolt("", new WordCount(), 4) .setNumTasks(8) .fieldsGrouping("splitProverb", new Fields("word")); // topology的配置文件 Config config = new Config(); try { if (args != null && args.length > 0) { // 说明是命令行执行 config.setNumWorkers(3); // args[0]传递的topology的名称 StormSubmitter.submitTopology(args[0], config, builder.createTopology()); } else { // 最大的任务并行度 config.setMaxTaskParallelism(20); LocalCluster localCluster = new LocalCluster(); // 提交一个topology localCluster.submitTopology("WordCountTopology", config, builder.createTopology()); // 测试环境运行1分钟 Utils.sleep(1 * 60 * 1000); // 然后关掉本地的测试 localCluster.shutdown(); } } catch (Exception e) { e.printStackTrace(); } } } -
错误一
java.lang.NoClassDefFoundError: org/apache/storm/topology/IRichSpout at java.lang.Class.getDeclaredMethods0(Native Method) at java.lang.Class.privateGetDeclaredMethods(Unknown Source) at java.lang.Class.privateGetMethodRecursive(Unknown Source) at java.lang.Class.getMethod0(Unknown Source) at java.lang.Class.getMethod(Unknown Source) at sun.launcher.LauncherHelper.validateMainClass(Unknown Source) at sun.launcher.LauncherHelper.checkAndLoadMain(Unknown Source) // 解决方式 把scope注释掉 // 如果使用最新的2.x的包,就是是注释了,也会出问题,因此这里用的1.2.3的版本进行测试 <dependency> <groupId>org.apache.storm</groupId> <artifactId>storm-core</artifactId> <version>1.2.3</version> <!--在本地模式运行的时候需要把下面的给注释掉--> <!--<scope>provided</scope>--> </dependency> -
问题二
java.lang.IllegalArgumentException: No matching field found: getConfiguration for class org.apache.logging.slf4j.SLF4JLoggerContext // 解决方式 <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter</artifactId> <!-- 因为日志包的冲突 这里把log4j-to-slf4j提出掉--> <exclusions> <exclusion> <groupId>org.apache.logging.log4j</groupId> <artifactId>log4j-to-slf4j</artifactId> </exclusion> </exclusions> </dependency> -
测试

storm集群运行
-
项目打包
mvn clean package -Dmaven.test.skip=true -
将jar包上传到服务器任意目录并允许
// 任意目录只适合配置了环境变量的机器,并通过以下规则指令运行 storm jar xxx.jar com.xxx.yyy.Topology(main对应的路径) arg0 arg1 arg2 如: storm jar storm-0.0.1-SNAPSHOT.jar com.lupf.shopstorm.wordcount.WordCountMain WordCountTopology // 下图的日志说明topology已经提交成功了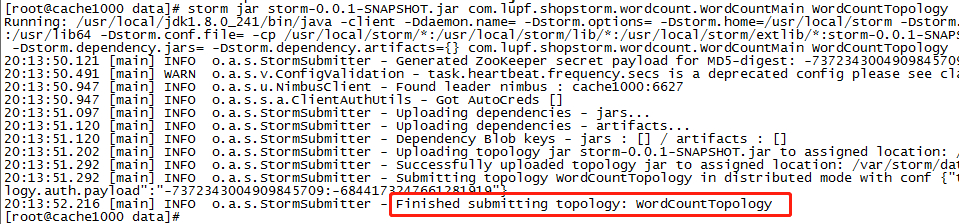
-
暂停服务
storm kill Topology名称 // 如: storm kill WordCountTopology#### 准备3台机器 -
cache1000:192.168.1.160 用来部署nimbus、ui管理平台和zookeeper
-
cache1001:192.168.1.161 用来部署supervisor 和 zookeeper
-
cache1002:192.168.1.162 用来部署supervisor 和 zookeeper
-
配置hosts
192.168.1.160 cache1000 192.168.1.161 cache1001 192.168.1.162 cache1002 -
下载最新的storm
// 这里包含了所有的版本 http://storm.apache.org/downloads.html // 下载2.1.0的版本 cd /usr/local/src wget https://mirror.bit.edu.cn/apache/storm/apache-storm-2.1.0/apache-storm-2.1.0.tar.gz
JDK 8安装及ZK集群安装
参考并发(七)之分布式异步更新:Zookeeper+Kafka实现数据分布式异步更新 ,其中包含了JDK的安装及zk集群的搭建
Storm部署
安装之前确保JDK 8和ZK已经部署好且能正常使用
-
解压
// 创建数据目录 mkdir -p /var/storm/data cd /usr/local/src/ tar -zxvf apache-storm-2.1.0.tar.gz mv apache-storm-2.1.0 /usr/local/storm cd /usr/local/storm -
修改配置
vim /usr/local/storm/conf/storm.yaml // 修改一下配置 #zookeeper集群的地址 #cache1000...跟别都是主机名 在/var/hosts配置了映射关系 storm.zookeeper.servers: - "cache1000" - "cache1001" - "cache1002" #zk的端口,默认就是2181 storm.zookeeper.port: 2181 #nimbus的主机 nimbus.seeds: ["cache1000"] #数据保存的本地路径 storm.local.dir: "/var/storm/data" #supervisor允许启动多少个端口,一个端口代表一个worker supervisor.slots.ports: - 6700 - 6701 - 6702 - 6703 #管理平台的端口,默认8080,防止冲突的话可以修改 ui.port: 8082 -
拷贝配置文件到其他机器
// 也可以手动拷贝 scp -r /usr/local/storm/conf/storm.yaml root@cache1001:/usr/local/storm/conf/storm.yaml scp -r /usr/local/storm/conf/storm.yaml root@cache1002:/usr/local/storm/conf/storm.yaml -
配置环境变量(可跳过)
// 为了方便,可以配置环境变量 vim ~/.bash_profile // 添加 export STORM_HOME=/usr/local/storm // PATH追加 :$STORM_HOME/bin // 刷新配置 source ~/.bash_profile // 其他机器可以使用scp拷贝过去 scp -r ~/.bash_profile root@cache1001:~/.bash_profile scp -r ~/.bash_profile root@cache1002:~/.bash_profile // 每台机器都刷新配置 source ~/.bash_profile // 测试环境变量 storm -h -
启动服务nimbus
// cache1000 启动nimbus 和 ui管理平台 // 配置了环境变量的启动方式 storm nimbus >/dev/null 2>&1 & storm ui >/dev/null 2>&1 & // 未配置环境变量的启动方式 cd /usr/local/storm/bin ./storm nimbus >/dev/null 2>&1 & ./storm ui >/dev/null 2>&1 & // 查看进程 jps | grep Nimbus jps | grep UIServer -
启动supervisor
// cache1001和cache1002启动supervisor // 配置了环境变量的启动方式 storm supervisor >/dev/null 2>&1 & // 未配置环境变量的启动方式 cd /usr/local/storm/bin ./storm supervisor >/dev/null 2>&1 & // 查看进程 jps | grep Supervisor -
管理页面
// 及图IP和主机名根据个人的实际情况来 // window别名访问需要在: C:\Windows\System32\drivers\etc\hosts 文件中配置别名映射 http://cache1000:8082
基于SpringBoot的词频统计
-
依赖
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter</artifactId> <exclusions> <!-- 因为日志包的冲突 这里把log4j-to-slf4j提出掉--> <exclusion> <groupId>org.apache.logging.log4j</groupId> <artifactId>log4j-to-slf4j</artifactId> </exclusion> </exclusions> </dependency> <dependency> <groupId>org.apache.storm</groupId> <artifactId>storm-core</artifactId> <version>1.2.3</version> <!--在本地模式运行的时候需要把下面的给注释掉--> <!--<scope>provided</scope>--> </dependency> <dependency> <groupId>com.codahale.metrics</groupId> <artifactId>metrics-core</artifactId> <version>3.0.2</version> </dependency> -
插件
<build> <sourceDirectory>src/main/java</sourceDirectory> <plugins> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-jar-plugin</artifactId> </plugin> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-shade-plugin</artifactId> <version>2.3</version> <configuration> <createDependencyReducedPom>true</createDependencyReducedPom> <filters> <filter> <artifact>*:*</artifact> <excludes> <exclude>META-INF/*.SF</exclude> <exclude>META-INF/*.sf</exclude> <exclude>META-INF/*.DSA</exclude> <exclude>META-INF/*.dsa</exclude> <exclude>META-INF/*.RSA</exclude> <exclude>META-INF/*.rsa</exclude> <exclude>META-INF/*.EC</exclude> <exclude>META-INF/*.ec</exclude> <exclude>META-INF/MSFTSIG.SF</exclude> <exclude>META-INF/MSFTSIG.RSA</exclude> </excludes> </filter> </filters> </configuration> <executions> <execution> <phase>package</phase> <goals> <goal>shade</goal> </goals> <configuration> <transformers> <!-- <transformer implementation="org.apache.maven.plugins.shade.resource.ServicesResourceTransformer"/> <transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer"> <mainClass>org.durcframework.core.MainCore</mainClass> </transformer>--> </transformers> </configuration> </execution> </executions> </plugin> <plugin> <groupId>org.codehaus.mojo</groupId> <artifactId>exec-maven-plugin</artifactId> <version>1.2.1</version> <executions> <execution> <goals> <goal>exec</goal> </goals> </execution> </executions> <configuration> <executable>java</executable> <includeProjectDependencies>true</includeProjectDependencies> <includePluginDependencies>false</includePluginDependencies> <classpathScope>compile</classpathScope> <mainClass></mainClass> </configuration> </plugin> </plugins> </build> -
创建Spout,用于源源不断的输出原始数据
import lombok.extern.slf4j.Slf4j; import org.apache.storm.spout.SpoutOutputCollector; import org.apache.storm.task.TopologyContext; import org.apache.storm.topology.OutputFieldsDeclarer; import org.apache.storm.topology.base.BaseRichSpout; import org.apache.storm.tuple.Fields; import org.apache.storm.tuple.Values; import org.apache.storm.utils.Utils; import java.util.Map; import java.util.Random; @Slf4j public class ProverbSpout extends BaseRichSpout { TopologyContext context; SpoutOutputCollector collector; Random random; /** * 做初始化相关的工作 * 如初始化连接池 * 创建http连接 等 * * @param map * @param topologyContext 拓扑上下文对象 * @param spoutOutputCollector 用于发射数据的collector */ @Override public void open(Map map, TopologyContext topologyContext, SpoutOutputCollector spoutOutputCollector) { context = topologyContext; collector = spoutOutputCollector; random = new Random(); } @Override public void nextTuple() { Utils.sleep(100); String[] proverbs = new String[5]; // 没谁瞧不起你,因为别人根本就没瞧你,大家都很忙的 proverbs[0] = "Nobody looks down on you because everybody is too busy to look at you"; // 深谙世故却不世故,才是最成熟的善良 proverbs[1] = "Thoroughly understanding the world but not sophisticated is the maturest kindness"; // 如果只是相见,却不能在一起,那宁愿从未相遇 proverbs[2] = "If we can only encounter each other rather than stay with each other then I wish we had never encountered"; // 当有人离开你的生活时,随他们去吧。这只是给更好的人留足了进入你生活的空间 proverbs[3] = "When someone walk out your life let them They are just making more room for someone else better to walk in"; // 要努力使每一天都开心而有意义,不为别人,为自己 proverbs[4] = "Strive to make every day joyful and meaningful not for others, but for myself"; int i = random.nextInt(proverbs.length); String proverb = proverbs[i]; // new Values就是构建一个tuple(元组) // tuple是最小的数据单元 // 无数个tuple组成的流就是stream log.info("发射谚语{}", proverbs); collector.emit(new Values(proverb)); } /** * 用于定义发射出去的tuple中field的名称 * * @param outputFieldsDeclarer */ @Override public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) { // 这里定义字段名称为proverbs(谚语) outputFieldsDeclarer.declare(new Fields("proverb")); } } -
创建句子拆分的Bolt
import org.apache.storm.task.OutputCollector; import org.apache.storm.task.TopologyContext; import org.apache.storm.topology.OutputFieldsDeclarer; import org.apache.storm.topology.base.BaseRichBolt; import org.apache.storm.tuple.Fields; import org.apache.storm.tuple.Tuple; import org.apache.storm.tuple.Values; import java.util.Map; public class SplitProverb extends BaseRichBolt { OutputCollector collector; /** * bolt的初始化方法 * * @param map * @param topologyContext * @param outputCollector bolt的tuple发射器 */ @Override public void prepare(Map map, TopologyContext topologyContext, OutputCollector outputCollector) { collector = outputCollector; } /** * 会接受到spout发射出来的谚语 * * @param tuple */ @Override public void execute(Tuple tuple) { String proverb = tuple.getStringByField("proverb"); String[] words = proverb.split(" "); for (String word : words) { collector.emit(new Values(word)); } } /** * 定于bolt发射出去的tuple中field的名称 * * @param outputFieldsDeclarer */ @Override public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) { // 这里定义为word outputFieldsDeclarer.declare(new Fields("word")); } } -
词频的Bolt
import lombok.extern.slf4j.Slf4j; import org.apache.storm.topology.BasicOutputCollector; import org.apache.storm.topology.OutputFieldsDeclarer; import org.apache.storm.topology.base.BaseBasicBolt; import org.apache.storm.tuple.Fields; import org.apache.storm.tuple.Tuple; import java.util.HashMap; import java.util.Map; @Slf4j public class WordCount extends BaseBasicBolt { // 统计词频 Map<String, Long> counts = new HashMap<>(); @Override public void execute(Tuple tuple, BasicOutputCollector basicOutputCollector) { // 获取到前一个task发射出来的tuple String word = tuple.getStringByField("word"); Long count = counts.get(word); if (null == count) { count = 0l; } count++; counts.put(word, count); log.info("{}词频{}次", word, count); } @Override public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) { // 声明field outputFieldsDeclarer.declare(new Fields("word", "count")); } } -
创建词频的Topology
import org.apache.storm.Config; import org.apache.storm.LocalCluster; import org.apache.storm.StormSubmitter; import org.apache.storm.topology.TopologyBuilder; import org.apache.storm.tuple.Fields; import org.apache.storm.utils.Utils; public class WordCountMain { public static void main(String[] args) { TopologyBuilder builder = new TopologyBuilder(); // 第一个参数 名称 // 第二个参数 实例化一个spout的对象 // 第三个参数 指定spout的executor有几个 builder.setSpout("proverbSpout", new ProverbSpout(), 2); builder.setBolt("splitProverb", new SplitProverb(), 4). setNumTasks(8) .shuffleGrouping("proverbSpout"); // 通过fieldsGrouping指定group的field可以将相同的单词发射到下游的同一个task中去 builder.setBolt("", new WordCount(), 4) .setNumTasks(8) .fieldsGrouping("splitProverb", new Fields("word")); // topology的配置文件 Config config = new Config(); try { if (args != null && args.length > 0) { // 说明是命令行执行 config.setNumWorkers(3); // args[0]传递的topology的名称 StormSubmitter.submitTopology(args[0], config, builder.createTopology()); } else { // 最大的任务并行度 config.setMaxTaskParallelism(20); LocalCluster localCluster = new LocalCluster(); // 提交一个topology localCluster.submitTopology("WordCountTopology", config, builder.createTopology()); // 测试环境运行1分钟 Utils.sleep(1 * 60 * 1000); // 然后关掉本地的测试 localCluster.shutdown(); } } catch (Exception e) { e.printStackTrace(); } } } -
错误一
java.lang.NoClassDefFoundError: org/apache/storm/topology/IRichSpout at java.lang.Class.getDeclaredMethods0(Native Method) at java.lang.Class.privateGetDeclaredMethods(Unknown Source) at java.lang.Class.privateGetMethodRecursive(Unknown Source) at java.lang.Class.getMethod0(Unknown Source) at java.lang.Class.getMethod(Unknown Source) at sun.launcher.LauncherHelper.validateMainClass(Unknown Source) at sun.launcher.LauncherHelper.checkAndLoadMain(Unknown Source) // 解决方式 把scope注释掉 // 如果使用最新的2.x的包,就是是注释了,也会出问题,因此这里用的1.2.3的版本进行测试 <dependency> <groupId>org.apache.storm</groupId> <artifactId>storm-core</artifactId> <version>1.2.3</version> <!--在本地模式运行的时候需要把下面的给注释掉--> <!--<scope>provided</scope>--> </dependency> -
问题二
java.lang.IllegalArgumentException: No matching field found: getConfiguration for class org.apache.logging.slf4j.SLF4JLoggerContext // 解决方式 <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter</artifactId> <!-- 因为日志包的冲突 这里把log4j-to-slf4j提出掉--> <exclusions> <exclusion> <groupId>org.apache.logging.log4j</groupId> <artifactId>log4j-to-slf4j</artifactId> </exclusion> </exclusions> </dependency> -
测试
storm集群运行
-
项目打包
mvn clean package -Dmaven.test.skip=true -
将jar包上传到服务器任意目录并允许
// 任意目录只适合配置了环境变量的机器,并通过以下规则指令运行 storm jar xxx.jar com.xxx.yyy.Topology(main对应的路径) arg0 arg1 arg2 如: storm jar storm-0.0.1-SNAPSHOT.jar com.lupf.shopstorm.wordcount.WordCountMain WordCountTopology // 下图的日志说明topology已经提交成功了 -
暂停服务
storm kill Topology名称 // 如: storm kill WordCountTopology
-
UI界面查看
// 具体地址根据个人的部署情况 http://cache1000:8082 // 即可看到相关的任务正在运行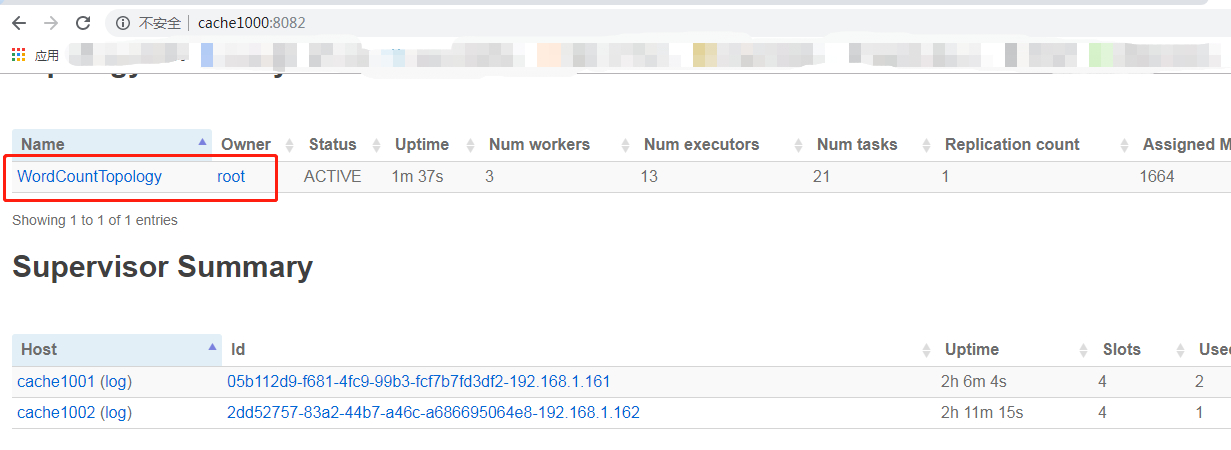
-
UI界面查看
// 具体地址根据个人的部署情况 http://cache1000:8082 // 即可看到相关的任务正在运行
标题:Storm2.x集群搭建及SpringBoot+Storm实现词频统计测试
作者:码霸霸
地址:https://lupf.cn/articles/2020/04/17/1587126422655.html