IDEA
IDEA
 Java
Java
 SpringBoot
SpringBoot
 面试题
面试题
 工具
工具
 JDK
JDK
Snowflake(雪花算法)分布式自增ID算法

问题说明
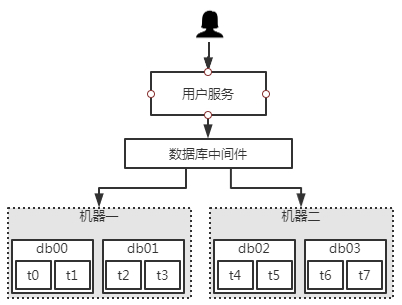
如,当我们将用户数据进行分库分表存储之后,如下图,当用户被分散4个库的8个表中,如何能保证ID的有序且唯一?那么这里就带出了一个分布式ID生成的问题。
解决方式
基于数据库
-
实现说明
当我们在插入数据的时候,优先插入一个不分库的表ID生成表,以数据库自增长的方式得到一个数据ID,如下图: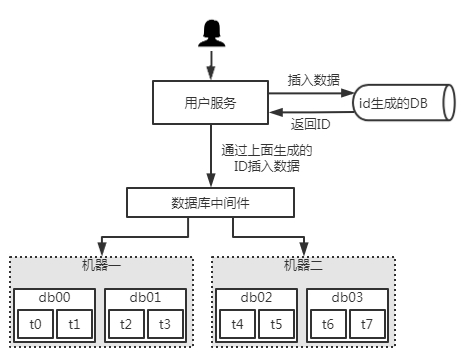
-
优点
- 简单
-
缺点
- 严重依赖ID生成的那个库
- ID生成在数据量大或者并发大的情况下会成为瓶颈
- 如果ID生成的库异常或者抖动将导致整个数据库无法正常使用
基于Redis
-
实现说明;
方式同上,只是将数据库更换成了Redis,然后通过INCR的操作得到一个唯一的自增ID,如下图: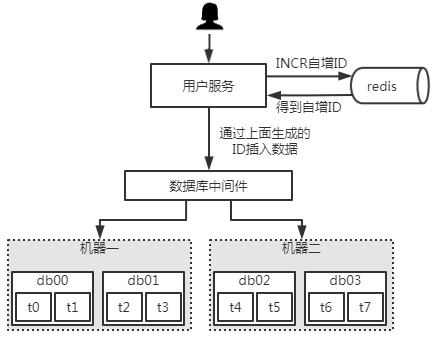
-
优点
- 简单
- 性能要优于上面的数据库方式
-
缺点
- 严重依赖Redis
- 当Redis异常将影响整个系统的使用
基于UUID
-
实现方式
String uuid = UUID.randomUUID().toString().replace("-", ""); // 3eb80015b95c4ed19885782edf9b3bd5 -
优点
- 简单高效
- 不需要依赖任何三方资源
- 相对适合做资源的id唯一
-
缺点
- 无法实现自增
- 当使用其作为主键的时候,由于太长性能会下降
时间戳加随机数
-
实现方式
Random random = new Random(); SimpleDateFormat df = new SimpleDateFormat("yyyyMMddHHmmssss"); // (random.nextInt(900000) + 100000) 随机生成一个6位的随机数 String date = df.format(new Date()) + (random.nextInt(900000) + 100000); -
优点
- 简单高效
- 不需要依赖任何三方资源
-
缺点
- 无法实现自增
- 无法保证绝对的唯一,有可能同一毫秒生成相同的随机数,虽然概率低,但是同样会出现
- 当使用其作为主键的时候,由于太长性能会下降
Snowflake算法(压轴推荐)
-
说明
Snowflake是Twitter推出的用于实现分布式自增ID的算法 -
数据结构
0 | 0001100 10100010 10111110 10001001 01011100 00 | 10001 | 00001 | 0000 00000000 0 | 0001100 10100010 10111110 10001001 01011100 00 | 10001 | 00001 | 0000 00000000 0 | timestamp |datacenterId| workerId | sequence 正数(占位) | 时间戳二进制 | 数据中心ID | 机器ID | 同一机房同一机器相同时间产生的序列 将上面组装好的二进制转化为十进制即为对应的ID -
优点
- 高效有序
- 不需要依赖任何三方资源
-
缺点
- 理解难道加大
- 存在一定的限制
-
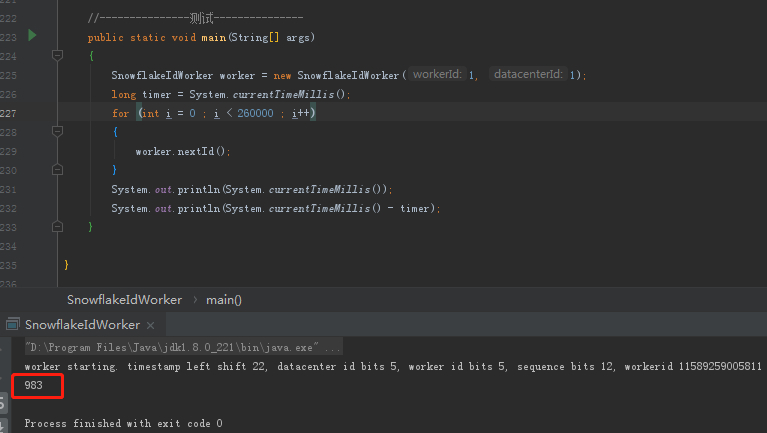
java代码实现(代码中有详细的说明,便于理解)
/** * 0 | 0001100 10100010 10111110 10001001 01011100 00 | 10001 | 00001 | 0000 00000000 * <p> * 0 | 0001100 10100010 10111110 10001001 01011100 00 | 10001 | 00001 | 0000 00000000 * 0 | timestamp |datacenterId| workerId | sequence * 正数(占位) | 时间戳二进制 | 数据中心ID | 机器ID | 同一机房同一机器相同时间产生的序列 */ public class SnowflakeIdWorker { // 数据中心(机房) id private long datacenterId; // 机器ID private long workerId; // 同一时间的序列 private long sequence; /** * 构造方法 * * @param workerId 工作ID(机器ID) * @param datacenterId 数据中心ID(机房ID) * sequence 从0开始 */ public SnowflakeIdWorker(long workerId, long datacenterId) { this(workerId, datacenterId, 0); } /** * 构造方法 * * @param workerId 工作ID(机器ID) * @param datacenterId 数据中心ID(机房ID) * @param sequence 序列号 */ public SnowflakeIdWorker(long workerId, long datacenterId, long sequence) { // sanity check for workerId and datacenterId // 机房id和机器id不能超过32,不能小于0 if (workerId > maxWorkerId || workerId < 0) { throw new IllegalArgumentException(String.format("worker Id can't be greater than %d or less than 0", maxWorkerId)); } if (datacenterId > maxDatacenterId || datacenterId < 0) { throw new IllegalArgumentException(String.format("datacenter Id can't be greater than %d or less than 0", maxDatacenterId)); } System.out.printf("worker starting. timestamp left shift %d, datacenter id bits %d, worker id bits %d, sequence bits %d, workerid %d", timestampLeftShift, datacenterIdBits, workerIdBits, sequenceBits, workerId); this.workerId = workerId; this.datacenterId = datacenterId; this.sequence = sequence; } // 开始的时间戳(2015-01-01) private long twepoch = 1420041600000L; // 数据中心(可以理解为机房)的ID所占的位数 5个bite 最大:11111(2进制)--> 31(10进制) private long datacenterIdBits = 5L; // 机器ID所占的位数 5个bit 最大:11111(2进制)--> 31(10进制) private long workerIdBits = 5L; // 这个是二进制运算,就是5 bit最多只能有31个数字,也就是说机器id最多只能是32以内 // 11111(2进制)--> 31(10进制) private long maxWorkerId = -1L ^ (-1L << workerIdBits); // 5 bit最多只能有31个数字,机房id最多只能是32以内 // 同上 private long maxDatacenterId = -1L ^ (-1L << datacenterIdBits); // 同一时间的序列所占的位数 12个bit 111111111111 = 4095 最多就是同一毫秒生成4096个 private long sequenceBits = 12L; // workerId的偏移量 // 0 | 0001100 10100010 10111110 10001001 01011100 00 | 10001 | 00001 | 0000 00000000 // 0 | timestamp |datacenterId| workerId | sequence // << sequenceBits private long workerIdShift = sequenceBits; // datacenterId的偏移量 // 0 | 0001100 10100010 10111110 10001001 01011100 00 | 10001 | 00001 | 0000 00000000 // 0 | timestamp |datacenterId| workerId | sequence // << workerIdBits + sequenceBits private long datacenterIdShift = sequenceBits + workerIdBits; // timestampLeft的偏移量 // 0 | 0001100 10100010 10111110 10001001 01011100 00 | 10001 | 00001 | 0000 00000000 // 0 | timestamp |datacenterId| workerId | sequence // << sequenceBits + workerIdBits + sequenceBits private long timestampLeftShift = sequenceBits + workerIdBits + datacenterIdBits; // 序列号掩码 4095 (0b111111111111=0xfff=4095) // 用于序号的与运算,保证序号最大值在0-4095之间 private long sequenceMask = -1L ^ (-1L << sequenceBits); // 最近一次获取id的时间戳 private long lastTimestamp = -1L; /** * 获取工作ID(机器ID) * * @return */ public long getWorkerId() { return workerId; } /** * 获取数据中心ID(机房ID) * * @return */ public long getDatacenterId() { return datacenterId; } /** * 获取最新一次获取的时间戳 * * @return */ public long getLastTimestamp() { return lastTimestamp; } /** * 获取下一个随机的ID * * @return */ public synchronized long nextId() { // 这儿就是获取当前时间戳,单位是毫秒 long timestamp = timeGen(); if (timestamp < lastTimestamp) { System.err.printf("clock is moving backwards. Rejecting requests until %d.", lastTimestamp); throw new RuntimeException(String.format("Clock moved backwards. Refusing to generate id for %d milliseconds", lastTimestamp - timestamp)); } // 判断本次的时间和前一次的时间是否一样 if (lastTimestamp == timestamp) { // 如果一样说明是同一时间获取多次 // 这个意思是说一个毫秒内最多只能有4096个数字,无论你传递多少进来,这个位运算保证始终就是在4096这个范围内,避免你自己传递个sequence超过了4096这个范围 sequence = (sequence + 1) & sequenceMask; // 如果与运算得到了0 说明sequence序列已经大于看4095 // 如4096 = 1000000000000 // 1000000000000 // & 111111111111 // = 000000000000 // = 0 if (sequence == 0) { // 调用到下一个时间戳的方法 timestamp = tilNextMillis(lastTimestamp); } } else { // 如果是当前时间的第一次获取,那么就置为0 sequence = 0; } // 这儿记录一下最近一次生成id的时间戳,单位是毫秒 lastTimestamp = timestamp; // 按上面的偏移量进行左移动 // 首位的0可以忽略 // 时间戳 << 22 | // datacenterId << 17 | // workerId << 12 | // sequence return ((timestamp - twepoch) << timestampLeftShift) | (datacenterId << datacenterIdShift) | (workerId << workerIdShift) | sequence; } /** * 切到下一个时间戳 * 作用是,当如果出现同一个时间戳内,获取的次数超过了4095 * 死循环至下一个时间戳,避免冲突 * * @param lastTimestamp * @return */ private long tilNextMillis(long lastTimestamp) { // 获取最新的时间戳 long timestamp = timeGen(); // 如果发现最新的时间戳小于或者等于序列号已经超4095的那个时间戳 while (timestamp <= lastTimestamp) { // 如果是小于或者等于的 那我们就继续死循环获取下一个时间戳 // 指导切换到了下一个时间戳 timestamp = timeGen(); } // 返回新的时间戳 return timestamp; } /** * 获取当前时间戳 * * @return 返回时间戳的毫秒数 */ private long timeGen() { return System.currentTimeMillis(); } //---------------测试--------------- public static void main(String[] args) { SnowflakeIdWorker worker = new SnowflakeIdWorker(1, 1); long timer = System.currentTimeMillis(); for (int i = 0 ; i < 260000 ; i++) { worker.nextId(); } System.out.println(System.currentTimeMillis()); System.out.println(System.currentTimeMillis() - timer); } } -
测试
大约1s可以生成26W+个唯一ID