 IDEA
IDEA
 Java
Java
 SpringBoot
SpringBoot
 面试题
面试题
 工具
工具
 JDK
JDK
为何 IDEA 建议去掉StringBuilder,使用“+”拼接字符串

各位小伙伴在字符串拼接时应该都见过下面这种提示:

内容翻译:报告StringBuffer、StringBuilder或StringJoiner的任何用法,这些用法可以用单个java.lang.String串联来替换。使用字符串串联可以使代码更短、更简单。只有当得到的串联至少与原始代码一样高效或更高效时,此检查才会报告。
大家普遍认知中,字符串拼接要使用StringBuilder,那为什么idea会建议你是用“+”呢,那到底StringBuilder 和 “+”有什么具体区别呢,我们一起来探究一下。
1、普通拼接
普通的几个字符串拼接成一个字符串,直接使用“+” 因为教材等原因,当前依旧有许多人拼接字符串时认为使用“+”耗性能1,首选StringBuilder。
实际上,从JDK5开始,Java编译器就做了优化,使用“+”拼接字符串,编译器编译后实际就自动优化为使用StringBuilder。
新建测试类StringTest,分别创建使用“+”拼接字符串和使用StringBuilder拼接字符串的方法;并新增Junit测试用例,分别调用拼接字符串100000次(这里不是循环拼接,而是执行多次拼接,因为一次拼接耗时太少,看不出差异),打印耗时。
/**
* 使用+拼接字符串
*/
public String concatenationStringByPlus(String prefix, int i) {
return prefix + "-" + i;
}
/**
* 使用StringBuilder拼接字符串
*/
public String concatenationStringByStringBuilder(String prefix, int i) {
return new StringBuilder().append(prefix).append("-").append(i).toString();
}
/**
* 测试使用+拼接字符串耗时
*/
@Test
public void testStringConcatenation01ByPlus() {
long startTime = System.currentTimeMillis();
int count = 100000;
for (int i = 0; i < count; i++) {
String str = concatenationStringByPlus("testStringConcatenation01ByStringBuilder:", i);
}
long endTime = System.currentTimeMillis();
System.out.println("testStringConcatenation01ByPlus,拼接字符串" + count + "次,花费" + (endTime - startTime) + "秒");
}
/**
* 测试使用StringBuilder拼接字符串耗时
*/
@Test
public void testStringConcatenation02ByStringBuilder() {
long startTime = System.currentTimeMillis();
int count = 100000;
for (int i = 0; i < count; i++) {
String str = concatenationStringByStringBuilder("testStringConcatenation02ByStringBuilder:", i);
}
long endTime = System.currentTimeMillis();
System.out.println("testStringConcatenation02ByStringBuilder,拼接字符串" + count + "次,花费" + (endTime - startTime) + "秒");
}
执行Junit用例,看耗时统计输出:
testStringConcatenation01ByPlus,拼接字符串100000次,花费33秒
testStringConcatenation02ByStringBuilder,拼接字符串100000次,花费36秒
虽然有差异,但是差异极小,考虑到执行了100000次,每次耗时的差异就更小了,而且程序执行有各种因素影响执行效率,可以认为耗时差不多。也可以多次执行对比耗时差异,也可以发现基本一致。
到class文件所在目录,执行 javap -c StringTest.class,对class文件进行反编译,查看编译后的代码差异。这里不要使用Intellij idea和JD进行反编译,因为反编译有优化,会都反编译成“+”拼接的,看不出来编译后的真正情况。
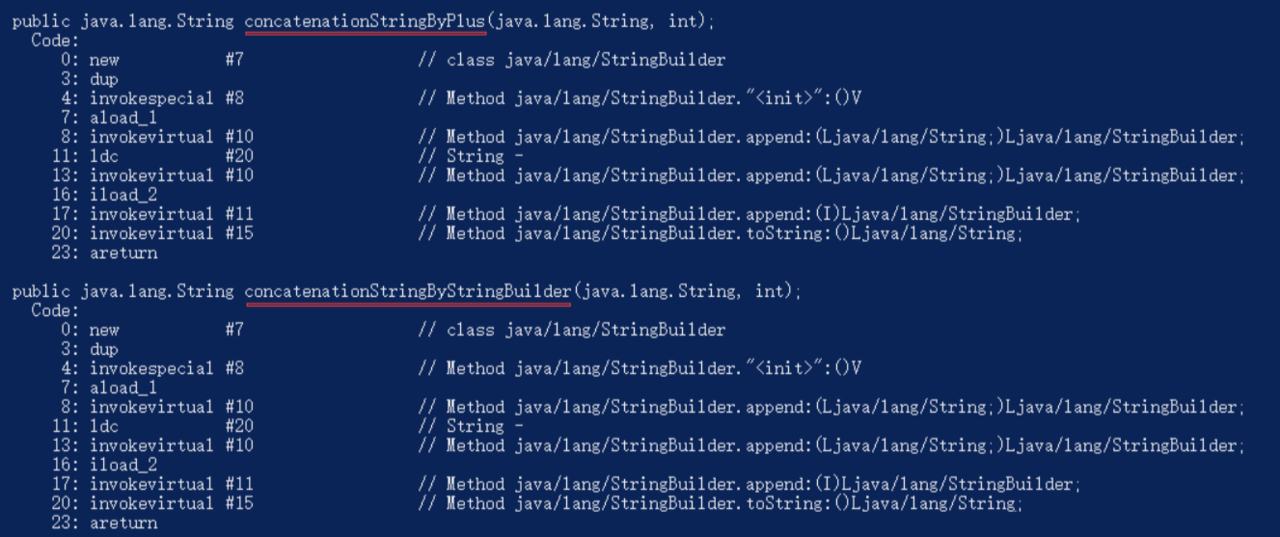
从图上可以看出两种拼接方法反编译后完全一样,没有差异,执行效率自然也是一样的。
既然执行效率一样,从代码简洁利于阅读考虑,推荐使用“+”拼接字符串。
2、循环拼接
循环拼接一个字符串,建议使用StringBuilder,虽然“+”拼接字符串编译后也会变成StringBuilder,但是每次循环处理都会new一个StringBuilder对象,耗时会大大增加。而直接使用StringBuilder,new一次就可以了,效率相对高。
新增2个Junit测试用例,循环拼接10000次拼接一个字符串(次数少于上面的用例,因为拼接的是一个字符串,如果拼接次数太多,可能引发内存溢出):
/**
* 循环使用+拼接字符串
*/
@Test
public void testLoopStringConcatenation03ByPlus() {
long startTime = System.currentTimeMillis();
int count = 10000;
String str = "testLoopStringConcatenation03ByPlus:";
for (int i = 0; i < count; i++) {
str = str + "-" + i;
}
System.out.println(str);
long endTime = System.currentTimeMillis();
System.out.println("testLoopStringConcatenation03ByPlus,拼接字符串" + count + "次,花费" + (endTime - startTime) + "秒");
}
/**
* 测试循环使用StringBuilder拼接字符串耗时
*/
@Test
public void testLoopStringConcatenation04ByStringBuilder() {
long startTime = System.currentTimeMillis();
int count = 100000;
StringBuilder stringBuilder = new StringBuilder("testLoopStringConcatenation04ByStringBuilder:");
for (int i = 0; i < count; i++) {
stringBuilder.append("-");
stringBuilder.append(i);
}
String str = stringBuilder.toString();
System.out.println(str);
long endTime = System.currentTimeMillis();
System.out.println("testLoopStringConcatenation04ByStringBuilder,拼接字符串" + count + "次,花费" + (endTime - startTime) + "秒");
}
执行Junit用例,看耗时统计输出:
testLoopStringConcatenation03ByPlus,拼接字符串10000次,花费463秒
testLoopStringConcatenation04ByStringBuilder,拼接字符串10000次,花费13秒
可以看出,差异明显,不在一个量级了。
总结
- 单纯的字符串拼接使用“+”,更快更简洁。
- 循环拼接时使用“+”拼接字符串效率较低,推荐使用StringBuilder。
作者:京东零售 姜波
来源:京东云开发者社区
标题:为何 IDEA 建议去掉StringBuilder,使用“+”拼接字符串
作者:码霸霸
地址:https://lupf.cn/articles/2023/11/15/1700059575318.html